Managed DevOps
The Impact of Round-the-Clock DevOps Support on Business Continuity

Despite the best of intentions, business continuity is always at risk from major IT disruptions. Whether it’s downtime due to insufficient resources or buggy software, your business will start bleeding money as soon as customers can’t spend theirs. Round-the-clock DevOps support is an essential part of today’s business continuity checklist.
Of course, if you haven’t been hit with a major disruption yet, 24/7 DevOps support may seem excessive. But the evidence suggests that all businesses get hit at one point or another, which, unfortunately, means it could be only a matter of time.
According to a report by the Uptime Institute, roughly 60%-80% of managers experienced some type of outage in the past three years. While the same study found that incidences of downtime are slowly decreasing, it also found that the cost of an outage is getting more expensive. The causes of these outages have remained relatively stable over the same period, with power and network outages and IT system failures being the leading causes:
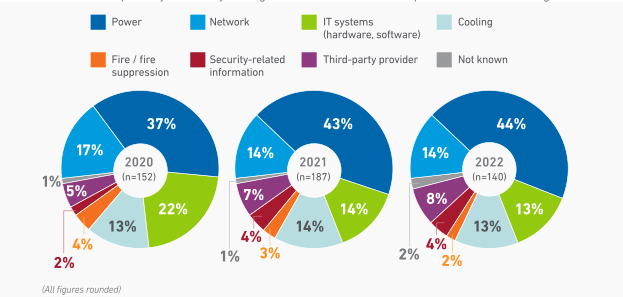
Whether you’re a devotee of Murphy’s law or not, outages tend to occur at the worst possible times and are often caused by high loads on systems and components. Upgrades and migrations, electrostatic discharge, and thermal issues with individual components are further contributors to downtime.
How 24/7 DevOps Support Boosts Business Continuity
The methodology used by DevOps to boost business continuity has been established and refined over recent years. It includes proactive 24/7 monitoring and remedial actions that span everything from performance to systems scaling and security.
Continuous Monitoring
As the name suggests, continuous monitoring refers to the act of keeping tabs on different parts of an organisation, with one of the main objectives being to ensure business continuity. Infrastructure, software, and security are commonly monitored for anomalies which, when detected, are investigated and proactively resolved before any such anomalies become serious issues. The data for these analytics are accumulated with the use of software tools like Prometheus, Monit, Datadog, and Nagios. These tools typically:
- Monitor infrastructure availability. Predictable availability is crucial to task service provision.
- Keep tabs on resource utilisation. Specifically, the efficient utilisation of available resources will ensure that tasks can be completed as needed, as opposed to suffering unnecessary delays.
- Track security, storage, permissions, the well-being of databases, network switches, performance, and so on.
In addition to helping companies keep track of performance issues and security events, continuous monitoring also helps companies keep track of the user experience by tracking feedback on events that could potentially impact the user experience such as upgrades or updates to software apps.
Rapid Incident Response
Incident response in DevOps relies on efficient responses to detected issues to ensure continuity or to at least minimise the duration of a system or component failure and subsequently restore normal operation. This requires a dedicated incident response team, automating the detection process and as much of the resolution process as possible, and, importantly, learning from each incident to build and optimise response policies that align with an organisation’s operational goals and customer needs. The incident management lifecycle puts this into practice:
- Detection: Monitoring tools (mentioned above) are used to collect and help analyse large amounts of data about infrastructure, applications, user interactions, and so on. Detected anomalies and critical events trigger an alert system that notifies the relevant team members.
- Response: The incident response team jumps into action. The faster the response and resolution, the less intense the impact on users and system performance.
- Resolution: The team works to resolve the incident and restore all systems to their previous operational state.
- Post-incident analysis: Once the incident has been resolved, a review is conducted to trace the root cause of the incident, and to identify any mistakes made during the resolution process along with corrective measures.
Implementation of this life cycle allows teams to manage incidents effectively and to enforce high levels of service quality.
Continuous Security
Given DevOps’ overarching role in IT and the fact that the DevOps team oversees so many critical operations, it stands to reason that it would also play an important role in security that serves to promote business continuity. This involves incorporating controls and security best practices, such as:
- Integrating security into the development and other organisational processes by conducting regular security reviews and tests
- Employing automation to enforce security policies and controls
- Audit and monitor systems for security vulnerabilities and compliance
- Implementing access controls to ensure that only authorised individuals have access to sensitive data and systems
- Regularly auditing and monitoring systems for security vulnerabilities and compliance with regulatory requirements.
- Evaluating and improving security practices and tools to match emerging threats and challenges
A key benefit of DevOps in a security context is the focus on continuous improvement by learning from previous experiences. Where security meets the need for uninterrupted business continuity, the benefit is cumulative over time.
High Availability Systems
Scalability refers to the ability of a system or application to perform tasks successfully and efficiently under load and is a key component of business continuity. Importantly, scalability refers to performance stability while workloads grow to ensure a seamless and consistent user experience. On the surface, this is achieved by adding more resources (e.g., storage, memory, processing power, network throughput, etc.) to a system.
In the context of DevOps, however, true scalability refers to designing systems that can grow efficiently as the need arises. The payoff is high availability systems that deliver rapid response times even when handling surges in traffic or resource demand. In the eyes of customers, this means reliability, which ultimately leads to customer satisfaction and retention.
An added benefit to the business—where scalability has been factored into system design—is cost savings; efficient resource utilisation eliminates the need to overprovision resources.
Conclusion
In today’s digital age, uninterrupted business operations are critical to maintaining customer trust and achieving long-term success. Round-the-clock DevOps support ensures continuous monitoring, rapid incident response, robust security measures, and scalable systems, all of which are essential for maintaining business continuity. Investing in 24/7 DevOps support not only mitigates the risks associated with IT disruptions but also enhances overall operational efficiency, leading to improved customer satisfaction and retention. For businesses aiming to stay competitive, round-the-clock DevOps support is not just an option—it’s a necessity.
More related news

Developers
Low-code + custom: when to use low-code tools in your SaaS stack (and when not to)
Low-code + custom: when to use low-code tools in your SaaS stack...

SaaS
Managing Unplanned Growth: Autoscaling & Cost Controls for Burst Traffic
When growth arrives unannounced – viral link, investor announcement, seasonal rush –...

SaaS
DevSecOps for UK SaaS SMEs: baking security into your pipeline without slowing down
Speed and safety no longer sit on opposite sides of the table....
Speak with a Storm Expert
Please leave us your details and we'll be in touch shortly
A Trusted Partner
